Keine Software und keine technische Infrastruktur ist perfekt: Störungen und Ausfälle sind keine Frage des "ob", sondern des "wann“ und "wie lange". Und der Ausfall eines Software-Systems ist immer kostspielig. Bei einem öffentlichen System können Kunden und User den Dienst nicht nutzen. Die Downtime eines internen Systems führt wiederum zu Produktivitätsverlusten und liegenbleibender Arbeit.
Deshalb ist natürlich jedes Unternehmen im Fall der Fälle bestrebt, eine Störung so schnell wie möglich zu lösen. Das geschieht allerdings häufig nicht besonders strukturiert. Ein exemplarisches Szenario wie das folgende dürfte sich in so mancher Organisation schon in ähnlicher Form abgespielt haben.
Ein Störfall und die allgemeine Hektik
Wenn etwas kaputt ist, dauert es nicht lange, bis Kunden sich im Unternehmen melden – beim Support, bei den Product Ownern in den Teams, bei ihren Kundenbetreuern. Im klassischen Szenario bricht nun Hektik aus.
Der Kundenbetreuer klemmt sich hinters Telefon oder in den Chat und trommelt alle möglichen Leute zusammen. Dass manche der Alarmierten schnell sehen, dass ja bereits Kollegen an dem Problem sitzen, ist erstmal zweitrangig. Der Kundenbetreuer geht bewusst nach dem Motto vor, besser zu viele als zu wenige oder die falschen Leute zu aktivieren.
Er löchert genervte Administratoren mit Fragen. Er weiß ja ebensowenig wie der Kunde, was warum wie lange schon kaputt ist und was dagegen unternommen wird und wie lange es dauern wird. Die Informationshäppchen, die er ergattert, gibt er sogleich an die Kunden weiter. Besonders valide und klar sind diese Details aber nicht.
Und mit seinen Fragen sitzt er weiterhin dem technischen Team im Nacken, das sich eigentlich mit der Behebung der Störung beschäftigt. In einem der Telefonate fährt ihn einer der IT-ler an: "Ich kann nur eine Sache gleichzeitig tun – telefonieren oder am Problem arbeiten. Also bitte: Was ist jetzt wichtiger?"
Alles in allem ist es eine stressige Zeit – für den Kunden, dessen Anwendung down ist, für den Kundenbetreuer, der in der Luft hängt und händeringend Infos sucht, für die Leute im IT-Team, die x Dinge gleichzeitig tun sollen und ständig durch hektische Nachfragen aus dem Fokus gerissen werden, für die Kollegen, die beim allgemeinen Alarm umsonst elektrisiert worden sind.
Am Ende ist eine Lösung erreicht und alles läuft wieder, aber richtig zufrieden ist keiner. Und wird jetzt eigentlich irgendwas unternommen, um eine Störung wie diese in Zukunft zu vermeiden?
Atlassian Opsgenie kann einem Störfall viel von seiner Schärfe nehmen.
Automatische Alarmierung und Eskalation
In Opsgenie stellen Bereitschaftspläne sicher, dass bei einer Störung die richtigen Personen benachrichtigt werden - und zwar automatisiert vom System. Wenn Opsgenie beispielsweise via Integration aus einem angeschlossenen Monitoring-System ein Problem detektiert (für Opsegenie stehen mehr als 200 Integrations für Drittanwendungen bereit), leitet es ohne manuelles Zutun die Alarmierung der richtigen Ansprechpartner in die Wege.
Die Kommunikationskanäle, über die Opsgenie diese Mitarbeiter alarmieren soll, sind vorher definiert worden – E-Mail, SMS, Telefon etc. Konnte eine Person auf einem Kanal offenbar nicht erreicht werden? Dann eskaliert Opsgenie den Vorgang und probiert es auf einem anderen Kanal und/oder bei einer anderen Person: In der Software können flexible Eskalationsstufen festgelegt werden. Opsgenie gibt nicht eher Ruhe, bis mit der Problembehebung begonnen wird.
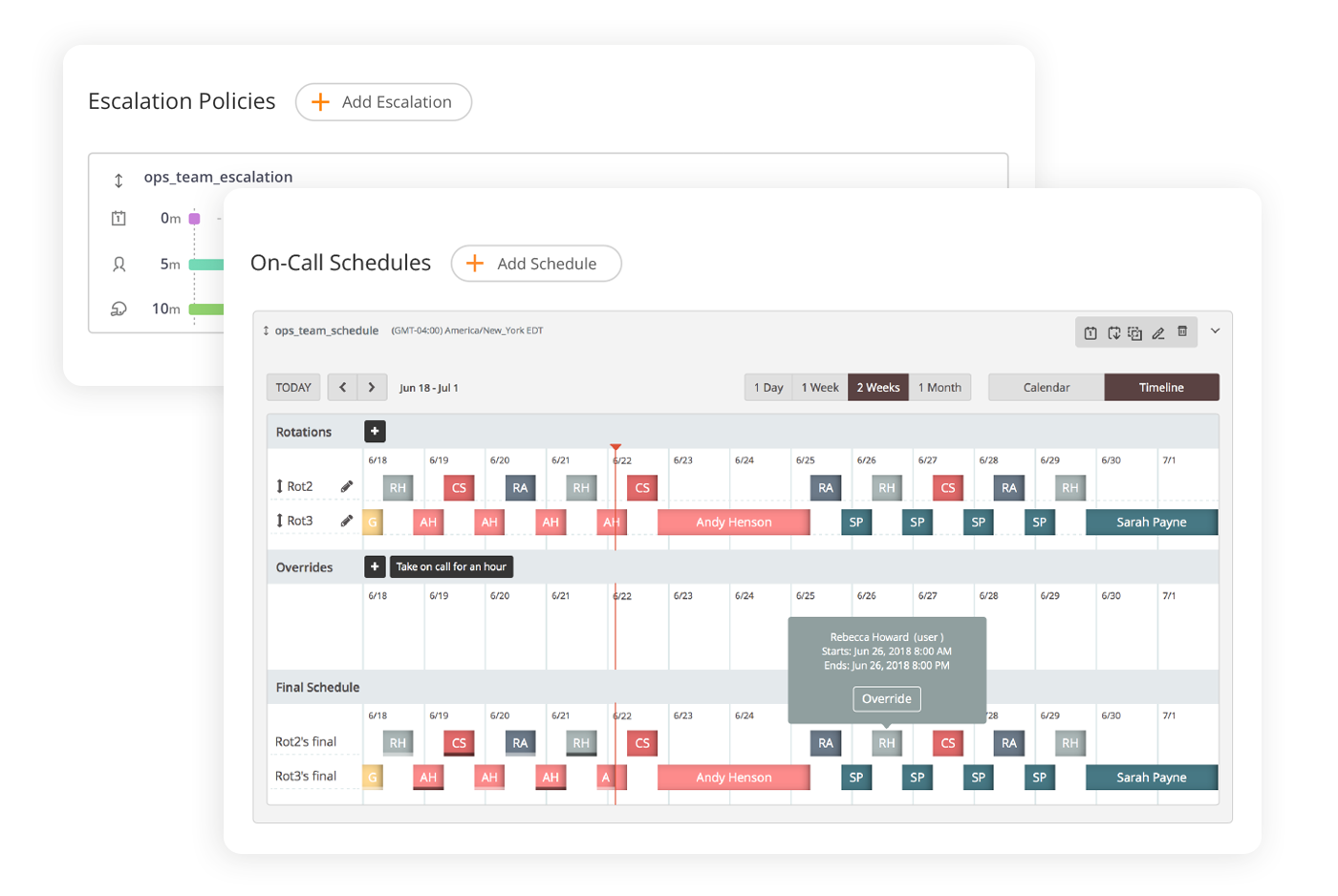
Flexibles Bereitschaftsmanagement in Opsgenie
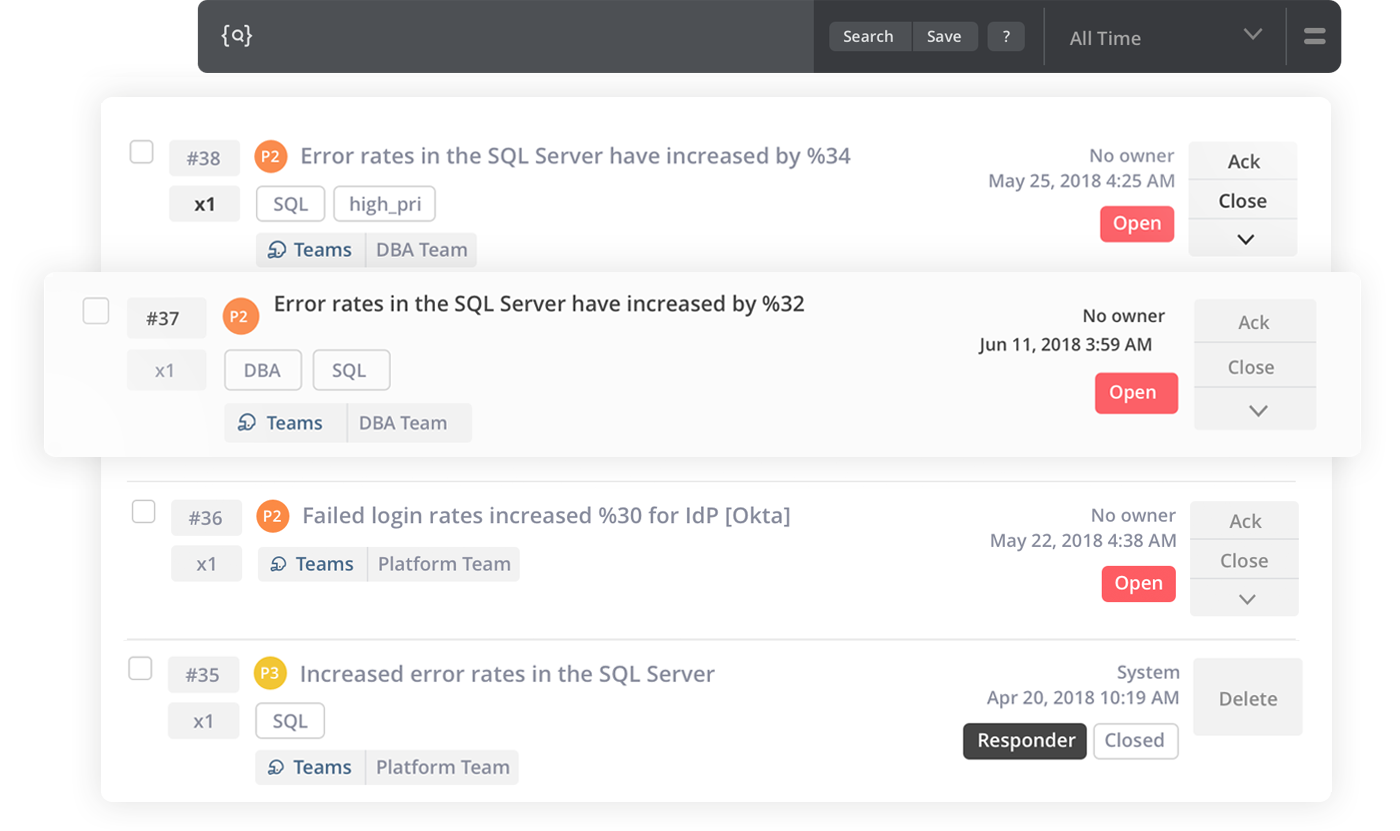
Opsgenie leitet bei erkannten Problemen selbständig die Alarmierung ein
Transparenz über den ganzen Prozess hinweg
Über die Problemeskalation besteht ebenso Transparenz wie über die folgende Bearbeitung des Vorfalls – und zwar auch für Leute wie den Kundenbetreuer aus dem Beispiel oben. Für Atlassian Opsgenie gibt es kostenfreie Stakeholder-Lizenzen, die es Personen außerhalb der unmittelbar involvierten technischen Teams erlauben, auf die aktuellen System- und Statusinformationen zuzugreifen.
Wer ist aktuell mit dem Problem befasst? Welche Maßnahme wird gerade ergriffen? Ein Stakeholder hat darüber jederzeit Klarheit. Er hat die Gewissheit, dass die richtigen Leute mit der Störung befasst sind. Es ist nicht nötig, Mitarbeiter manuell zu alarmieren. Es ist nicht nötig, die konzentrierten Admins zu löchern, um Informationshäppchen zu bekommen. Der Kundenbetreuer sieht alles live im System und kann bei Bedarf valide Details zum Status quo der Problemlösung an Kunden herausgeben.
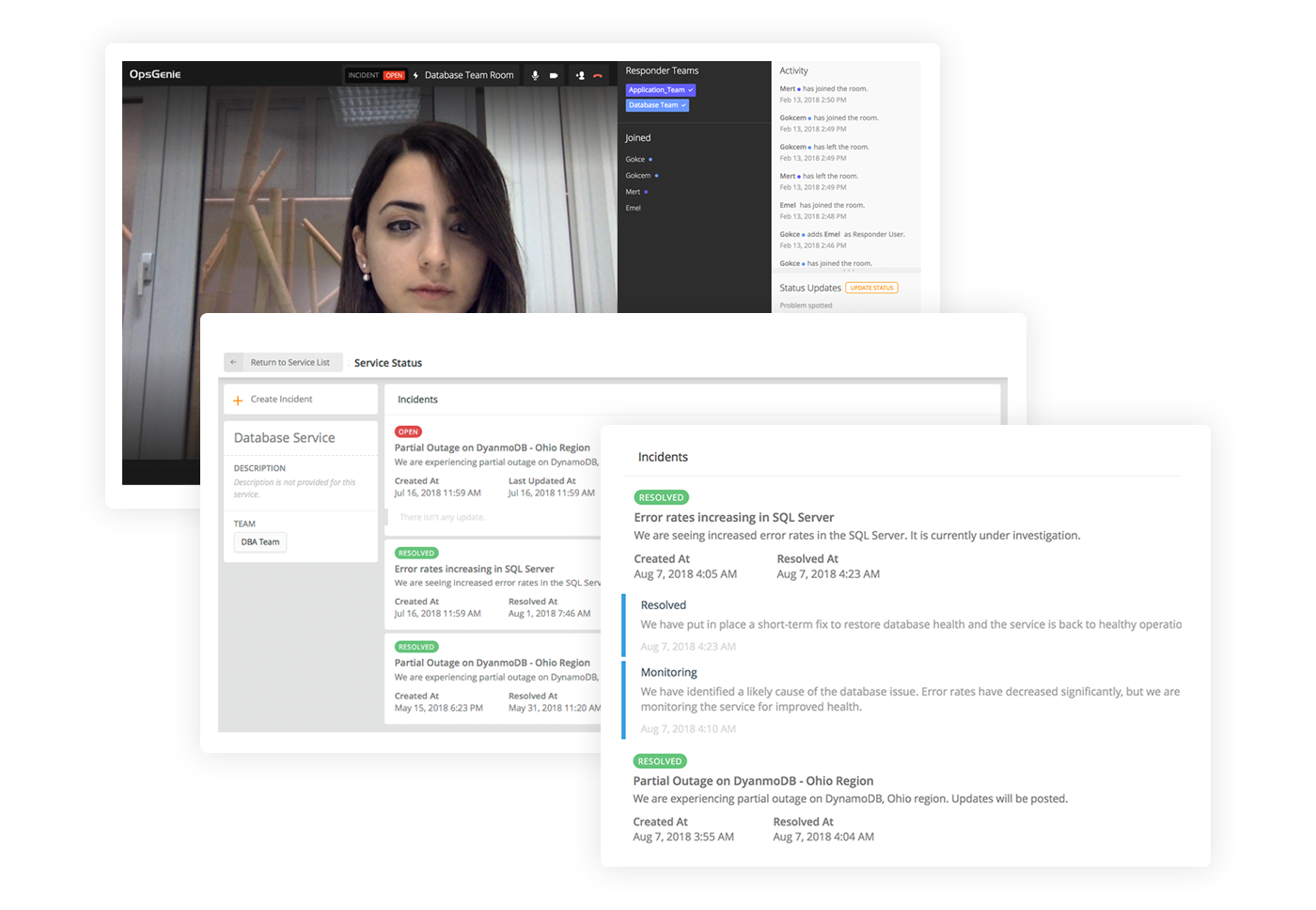
Opsgenie bietet über den gesamten Incident-Management-Prozess hinweg Sichtbarkeit
Datenbasis für die Nachbereitung
Damit die administrativen Teams nicht der (verständlichen) Versuchung erliegen, nach der Erledigung eines Problemfalls einfach zum Tagesgeschäft überzugehen und sich ihren sonstigen Aufgaben zu widmen, bietet Opsgenie Funktionen für sogenannte Postmortem-Analysen. Damit ist die strukturierte Nachbereitung eines Vorfalls gemeint, um ähnliche Probleme in Zukunft möglichst zu vermeiden: Aus Herausforderungen zu lernen, ist heute nicht weniger wichtig, als sie zu lösen.
Das System hält detaillierte Berichte vor, die die Datenbasis solcher Analysen bilden können. In Verbindung mit Confluence und entsprechenden Bereichs- und Seitenvorlagen für eine umfassende Auswertung kann das Team Störungen systematisch nachbereiten. Folgeaufgaben, die sich daraus ergeben, bildet das Team idealerweise in einem verknüpften Jira-System. Jira Ops, an dem Atlassian derzeit intensiv arbeitet, wird hierfür diverse Features und Automatisierungen mitbringen.
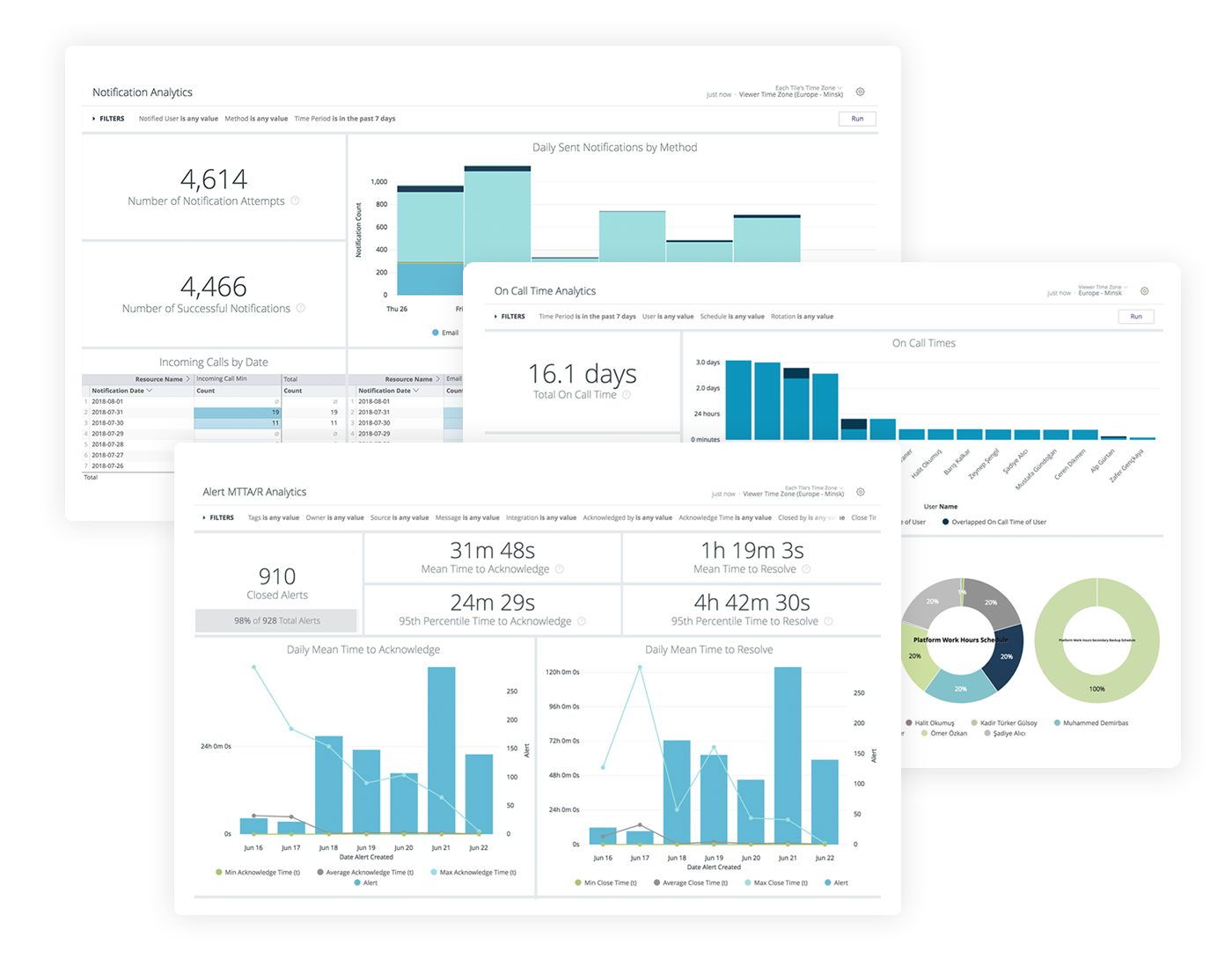
Das umfangreiche Datenmaterial zu jedem Vorfall unterstützt Postmortem-Analysen
Mit Atlassian Opsgenie haben Unternehmen ein Werkzeug an der Hand, um ein systematisches Incident-Management aufzubauen und es in einen flexiblen, automatisierten, nachvollziehbaren Prozess zu lenken. Es räumt den beteiligten Admin-Teams viel Flexibilität ein, hilft zu gewährleisten, dass die richtigen Mitarbeiter schnell an der Problemlösung arbeiten, und schafft Sichtbarkeit und Sicherheit. Darüber hinaus bietet Opsgenie das Datenmaterial, das nötig ist, um aus einem Vorfall die richtigen Schlüsse zu ziehen.
Wir sind Ihr Partner für Atlassian Opsgenie
Möchten Sie mehr über Atlassian Opsgenie erfahren? Würden Sie gerne direkt über den Aufbau eines strukturierten Alerting-Prozesses für konkrete Anwendungen in Ihrem Unternehmen sprechen? Dann melden Sie sich bei uns: Wir sind Atlassian Platinum Solution Partner und unterstützen Sie gerne bei allen Aspekten eines systematischen Incident-Managements in Ihrer Organisation.
Weiterführende Infos
Atlassian Opsgenie: Einführung zu Nutzenversprechen, Anwendungsfällen und Funktionen
Incident-Management: Postmortem-Prozesse mit Jira Ops
Warum Anbieter von Web-Anwendungen Statusseiten brauchen
Atlassian-Lizenzen bei //SEIBERT/MEDIA kaufen – alle Vorteile



